Blog: On Storing Passwords: A Better Way?

How are passwords typically stored?
Most (correctly configured) applications and operating systems use a one-way cryptographic hash to store passwords. A one-way hashing algorithm (e.g. MD5, SHA1, SHA2) reduces a string of bytes of arbitrary length to a fixed length digest, or "hash." Hashes have properties that make it very useful for storing passwords:
- The hash is non-reversible: you cannot derive the original text from the hash.
- Hashes are deterministic: the same input for a given hashing function always yields the same hash.
- Collision resistance: The output hash is the same size for any given algorithm, so there must be multiple different plaintext inputs that would yield the same hash. However, this phenomenon (called a collision) must be computationally infeasible to produce. That is one cannot determine, given an input/hash pair, some other input that would yield the same hash.
- A small change of even 1 byte in any given input text should yield a substantial difference in the resulting hash:
- Example:
MD5(DOG) -> b0e603b215aa2da0e6c605301d79efe4
MD5(DOg) -> 1bff10c250290792853fd12f0c2e55e2
There are other properties, however this should be sufficient as a high level introduction. Far more detailed information can be found on the Wikipedia page.
In its simplest form, the process for authenticating via password works like this:
User provides a password -> Run the password through a hashing algorithm -> output compared to previously stored hash value.
Why might we want a slightly different option?
One drawback to the irreversibility of a cryptographic hash, are instances when being able to produce original plaintext passwords would be useful. An example might be the desire to compare a proposed new password against a previously used one.
A better way (or a different one):
In a conversation I had on Twitter a few weeks back, the question was asked: "How could a vendor check similarity to a previous password without storing the passwords in clear text?"
For example, the website in question was able to do something like this:
- Say your old password (the one you're changing) is "stinkfeet"
- You attempt to change this from "stinkfeet" to "chicagofan"
- The system replies with something like: "New password is too similar to old password, too many of the same characters in the same position"
- It knows that a PREVIOUS password (not the most current one, but maybe 1, 2, 3 or x passwords ago) was "chicagoguy".
Then, since chicagofan / chicagoguy are more than 50% similar, you get that error.
How is this possible, given only the method described above? The original question is a good one, their assumptions (correctly) were:
- System probably stores passwords using one-way hashes like MD5, SHA1, SHA2 or a Key Derivation Function (KDF) used as a hashing algo (more on this later).
- The user didn't enter any other data other than their last password and the new one.
- No way the system could have known the proposed new password was similar to an N-1..X older password without having that old password stored in the clear.
Right? Yes. But - there is another way, read on...
Instead of storing the user's password as a one-way hash, use the password to generate a hash (hereafter referred to as a key) and use that key as input to an encryption algorithm, such as AES128, and use that algorithm to encrypt the user's password and profile data (and anything else you might want to keep secure, such as historical passwords.)
At it's most simple, just doing basic authentication with username / password the steps are this:
- User enters a username and password.
- The system uses a KDF like PBKDF2 or SCRYPT to generate a Key of say 16 bytes from this password. There is another advantage to using one of these KDFs, which I'll mention later.
- The generated Key is used to decrypt ciphertext (using a symmetric cipher like AES128) stored in the password file associated with this user's ID (like a shadow file).
- The resulting plaintext is the user's username which is compared with the username used to login. If they match - user is authenticated.
- In this solution, no representation of the current password is ever stored on disk. Only the ciphertext resulting from encrypting the User's name.
A diagram might be useful:
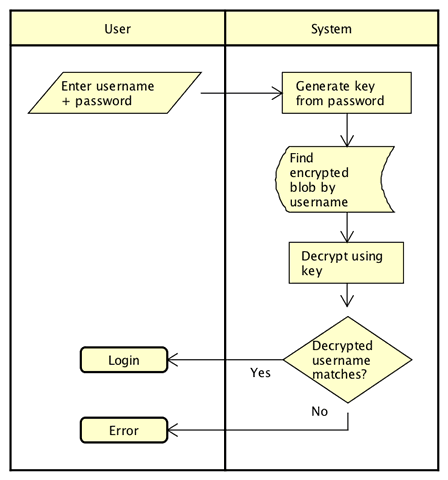
Taking this a step further, there's no reason to limit the encrypted data to just the user's username. The system could also store authorization to system resource data, and other sensitive data, such as: previous (plaintext) passwords.
Now the scenario from the Twitter conversation would work as follows:
- User enters a username and password.
- System uses the password as input to a KDF and generates a key.
- The key is used to decrypt (using a fast symmetric cipher, like AES128) a record stored in the security database.
- A decrypted field in the database that stores the user's username is compared with the username they entered. It matches!
- System recognizes it is time to change the password and prompts the user for a new one.
- User enters proposed new password.
- System compares the proposed new password to X number of saved historical passwords (stored inside the user's, now decrypted, security record).
- Tells you the proposed one is too close to an old one and so on.
- New password is accepted and used to generate a new key with the KDF.
- Security record is updated with the plaintext version of the most recent old password and bumps the oldest one off the list.
- Finally, security database record for the user is encrypted using the key generated with the new password.
Phew. That may seem like a huge number of steps, or that it is overly complicated - but does have the benefit of solving for the scenario we described - preventing users from slightly altering a recent historical password by storing encrypted copies of old passwords.
This could be a drawback too, as a compromised current password would give a would-be attacker access to a trove of old passwords. This can be mitigated by using two-factor authentication, using long passphrases, and using an adjustable memory-hard function (more on this shortly).
What about that KDF? And what is this memory hard business?
Properly implemented, this solution (and others) can use an adjustable KDF as a sort of throttle against offline-brute force attacks. This password-key-encryptedDB solution is just as vulnerable to offline password cracking as any other (See RACF passwords in John The Ripper or oclHashcat - they work exactly this way).
It's beyond the scope of this post to get deep into that, but simply put: An adjustable KDF has parameters that can be adjusted, that intentionally slow down the time it takes the CPU to compute the hash/key. Why is this desirable? Because to a user, a hash that takes 1 microsecond vs one second to compute isn't noticeable, but for a brute force operation, that will slow the number of operations down by a factor of 1,000,000. Going from a hypothetical billion hashes per second to 1,000 hashes per second. That is significant. If you want more information on how this works see:
https://www.tarsnap.com/scrypt/scrypt.pdf
https://www.bigendiansmalls.com/encryption_at_share/
https://www.cryptolux.org/images/d/d1/Tradeoff-slides.pdf
Questions? Comments?
Find Chad Rikansrud on Twitter: @bigendiansmalls
Blog: https://www.bigendiansmalls.com
Montreal 2017 sponsored by